
文書から隠れた主題(トピック)を抽出する解析手法。文書だけではなく、購買履歴、視聴コンテンツ、ソーシャルネットワーク、画像、音楽、クチコミ、流行、ゲノムなど様々な分野での活用事例が報告されている。
AIの基盤技術として多くのビジネスマンの間で知られるようになったディープラーニングの知名度には及ばないが、先進的な企業が活用して成果を上げていることでひそかに注目されているデータ解析手法がいくつかある。トピックモデルはその代表格である。
元々は自然言語解析の研究分野で考案された手法で、文書は複数の潜在的な話題(トピック)から生成されると仮定している。例えば、「メジャー挑戦を表明した大谷翔平選手はグレーのスーツに紺色のネクタイ姿で会見場に現れた」という文書にプロ野球という単語は出てこないが、そのトピックが「プロ野球」と言われても違和感はないだろう。これは大谷翔平選手やメジャーという単語がプロ野球に関する記事や文書に出現する機会が多く、これらの単語が使われている新しい文書のトピックは「プロ野球」と推測できるからである。一方、「スーツ」「ネクタイ」「グレー」「紺色」はファッションの記事で見られる単語なので、この文書には 「ファッション」というトピックもあるかもしれない。
トピックモデルでは、文書は複数のトピックから生成され、単語は各トピックが持つ単語の出現分布に従って文書内に生成されると仮定し、その生成過程を確率で表現する。
PLSAの概要図
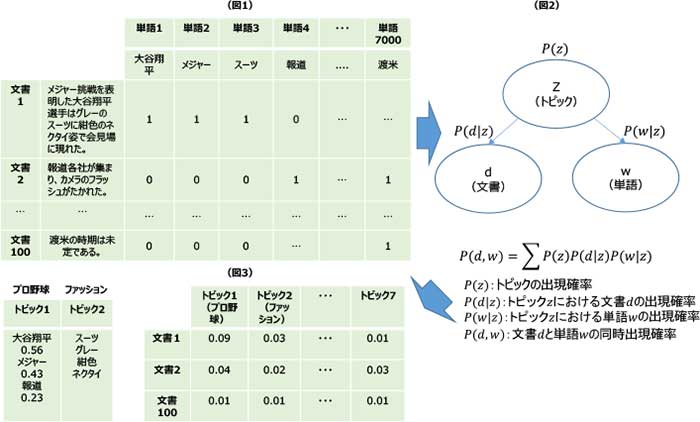
(図1)行に文書を、列に出現した単語を置いたテーブルを用意する。(BOW表現。Bag-of-Words)
(図2)膨大な数の単語をPLSAで少数のトピックに変換する。
(図3)各トピックに所属する単語から解釈してトピック名称を付ける。各文書における各トピックの所属確率が推定される(スコアは架空)。
図は同モデルの一種であるPLSA(確率的潜在意味解析法)による過程を示したものである。文書と単語をそれぞれ行と列に置いて、各文書における単語の出現頻度を集計する。確率変数P(z)、P(d│z)、P(w│z)からP(d,w)=ΣP(z)P(d│z)P(w│z) を導く。
ビジネスで、このモデルを活用する企業は多い。ECサイトを運営する企業では、自社が取り扱う膨大な数の商品アイテムに付いている説明文やユーザーの評価からトピックを抽出し、そのトピックに関心があるユーザーに対して商品を推奨するシステムを構築している。文書以外にもこのモデルを適用したPOSデータの場合、商品が文書における単語で、商品の購入者を文書と見なせば、抽出されたトピックは購入者の興味や好みを表していると解釈できる。購入者の側から見れば「何の商品を買いやすいか」、商品から見れば「誰に買われやすいか」が把握できるので、似たような好みを持つ購入見込み者に対して商品情報を薦める、という仕組みも考えられる。商品に限らず視聴するテレビ番組、購読する雑誌、閲覧している動画サイト、好きなタレント、訪れた街などのデータでも同様の解析が可能である。
音楽では、歌詞の内容から抽出したトピックに属する楽曲や歌手を検索する方法が提案されている。画像では、洋服の画像から抽出した特徴量をモデルに適用し、コーディネートを推奨する研究も行われている。音声や画像をSNS上に投稿する行為が今後ますます一般化すると思われるので、この領域におけるトピックモデルの活用事例がさらに増えると予想する。
トピックの出現を事前分布で表現するLDA(潜在的ディリクレ配分法)や、時系列の変化を想定したDTM(ダイナミック・トピック・モデル)などデータの特性に応じた拡張モデルの多くが提案されている。データドリブンなビジネスを目指す企業ならば、様々なデータに適用できて、他の解析手法とも併用できるこのモデルを積極的に自社のビジネスに使ってみる価値は十分にあるだろう。

アサツー ディ・ケイ M&D事業統括本部 R&D局長
メーカー勤務を経て1999年アサツー ディ・ケイ入社。
主に研究開発部門に所属し、ブランディング手法の開発や、統計・機械学習手法を活用したマーケティングデータ解析などを担当。日本広告学会会員。日本消費者行動研究学会会員。2017年より現職。


