

マルチモーダルAIとは、複数の異なるデータを扱えるAIのこと。OpenAI社のGPT-4o等が代表的であり、入出力時にテキスト・画像・音声等を扱える技術である。人間のような複雑な情報処理を模擬した振る舞いができるため、自動運転をはじめ各所への応用が期待される。
複数データを組み合わせ高度な認識を実現するAIの登場
「GPT-4o(omni)」とは、米OpenAI社により2024年5月13日(現地時間)に公開された生成AIモデルGPTシリーズの最新モデル※1である。ユーザーからテキストのみならず、音声・画像・動画のあらゆる組み合わせを入力可能である点が特徴であり、出力に関してもテキスト・音声・画像のいずれの組み合わせも可能となっている。
これまでにもChatGPTも音声入力は可能であったが、平均2.8秒(GPT-3.5)から平均5.4秒(GPT-4)の遅延が発生することが知られている。
これは「(1)音声からテキストへ変換するモデル」「(2)テキストからテキストを生成するモデル」「(3)生成されたテキストを読み上げる音声モデル」の3つの個別モデルを段階的に処理することに起因する。
対して、GPT-4oではテキストも音声も単一のモデル内で訓練されている(;入出力が同じニューラルネットワークで処理される)ため、音声入力に対して平均320ミリ秒で応答可能という人間の応答速度に近く、最新のAIにふさわしい体験を実現した。
▲米OpenAIのGPT-4o(omni)では、まるで人間同士が会話するかのような音声入力・応答の体験が驚きとともに大きな注目を集めている。(出典:YouTube)
GPT-4oのように複数の異なるデータ(モダリティ)を1つのAIモデルで扱うことができるものは「マルチモーダルAI」と呼ばれる。マルチモーダルAIの研究は1980年代半ばには重要性が指摘されていたが、近年は特にGPTシリーズのような大規模言語モデル(LLM, Large Language Model)にモダリティを持たせたマルチモーダルLLMが注目を集めている。
GPT-4oへつながるマルチモーダルAIの発展は、OpenAI(2021年)から発表された「CLIP(Contrastive Language-Image Pre-training)」と呼ばれる視覚概念を自然言語との間で効率よく学習する手法※2や、DeepMind(2022年)が提案した視覚的な特徴をVisual Encoder/Perceiver Resamplerにより言語モデルへ入力可能とした「視覚言語モデル(VLM, Visual Language Model)Flamingo」といった研究の延長線上に続いているものである。
他方でマルチモーダルAI(またはマルチモーダルLLM)というトピックがこれほどまでに注目されたのは、ChatGPTに始まったLLMブームが後押しとなったことは言うまでもない。
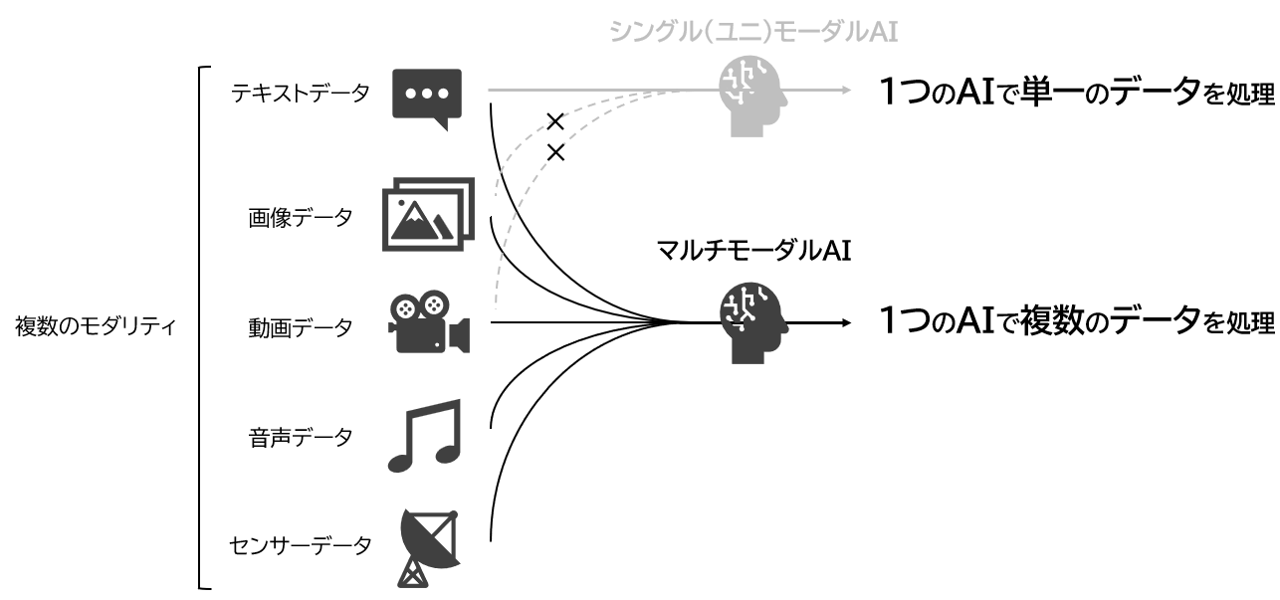
▲マルチモーダルAIでは複数のデータを単一のAIで処理することで高度なやり取りを実現できる(図は筆者作成)
マルチモーダルAIは人間のような推論を実現する
ここで思考実験として、例えばテレビ画面に流れている猫の映像を見ている時を思い浮かべてみたい。

▲テレビに映っている猫の映像。図は画像生成AI「Midjourney」にて筆者作成
はじめに消音されたテレビの場合、映像として流れる猫は大きく口を開けており、まるで何か「ミャー」といった鳴き声をあげているかのように私たちは理解するだろう。
この時、眼より視覚情報として入力された猫の映像に対して、私たちの記憶や知識の中の猫の様子と照合して「猫が鳴いている様子」と推論するわけであり、一見すると妥当な結果に思える。

▲小さく息を吐きながら「フワァァ・・・」と口を開けている音声と共に猫の映像が流れる。
次にテレビの音を出しながら猫の映像を改めて見たところ、猫が「フワァァ・・・」と息を吐きながら口を開けていることがわかったとしよう。私たち人間は音声と視覚情報を組み合わせ、お互いに関連付けながら「あくびをしている猫の映像」と推論するのではないだろうか。この結果は先の消音時の結果と異なるが、より高度な推論に基づく結果といえよう。
このように1つの入力、1つの出力に制限されずに複数のモダリティを扱えることは「より高度な推論」「より高度な問題解決」「より高度な生成」を可能となる。これが「マルチモーダルAI=人間のようなAI(汎用人工知能とも呼ばれる)の可能性を秘めた技術」として注目される最大の理由である。
「人間のようなAI」は生活者の体験を変革させるのか
マルチモーダルAIは、テキスト、画像、音声、動画など複数のデータ形式を統合して処理できるためこれまでにない新たな体験を生活者へ提供すると予想される。
その代表的な例が自動運転である。私たちが車を運転する時には単純に視覚から入る情報以外にも、周辺の音や運転する車のスピード等の計測値等を確認しながら運転しており、人間は複数の入力を瞬時に処理し続けるという極めて高度な処理をしている。
米テスラ社は2024年10月に米ロサンゼルスで開催されたイベント「We, Robot」にて完全自動運転を体現した同社のコンセプトとして、Cybercabを発表した。Cybercabのコンセプトムービーでは運転手はハンドルを握っていないのみならず、乗客が社内で睡眠している様子もある。
同イベントでは、Cybercabは人間の機能を全て代替した完全自動運転の実現が言及された。「自動車による移動=運転する時間」が「自動車による移動=エンターテイメント、休暇、睡眠、etc. の時間」といった全く新しい生活者体験を実現しようとしている。
このようにマルチモーダルAIは既存の様々な制約を解消する可能性を秘めており、全く新しい生活者への体験価値を提供するポテンシャルを秘めた注目すべき技術の1つといえよう。
▲米テスラのCybercabでは、マルチモーダルAI技術を用いた自動運転により、新しい移動時間の体験の提供を目指している。(出典:YouTube)
※1:OpenAI社の最新モデルとしてはOpenAI o1が2024年9月12日(現地時間)に発表された。GPT-4oがテキスト・音声・画像・ビデオのあらゆる組み合わせを入力可能なモデルであるのに対し、o1では複数のモダリティの入力はできない一方で、広範な一般知識を用いて高度な推論能力を発揮することが特徴であり、これまでのGPTとは別シリーズとされている。
※2:CLIPの直感的な説明としてはテキストと画像データを対応させたペアに対して、新たに与えられた画像の類似性の近さを計算する仕組みであり、識別モデルに近い。OpenAI社が提供する画像生成AIであるDALL-E・2のアーキテクチャとして採用されていることが知られている。
<参考文献・引用文献>
-
”Introducing OpenAI o1”, OpenAI. https://openai.com/o1/, (accessed by 2025-01-31).
-
JB Alayrac, et al. " Flamingo: a Visual Language Model for Few-Shot Learning", 36th Conference on Neural Information Processing Systems. NeurIPS, 2022.
-
Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International Conference on Machine Learning. PMLR, 2021.
-
” Cybercab | The Future is Autonomous”, Tesla. https://www.youtube.com/embed/Qfj4urMF8CU, (accessed by 2025-01-31).
ADKマーケティング・ソリューションズ
DX推進局 R&D推進グループ グループ長/プランニングディレクター

新卒で鉄鋼メーカー入社後、社費留学による大学派遣などを経て数値流体解析や機械学習を活用した研究開発に従事。美大編入、NTTデータにおけるコンサルティング経験を経て、2023年より現職。AI/ML領域を中心とした研究開発やプランニングを行う。Azure OpenAIを活用した社内GPTチャットボット「トラポケ」の開発推進、ADK社内のAI推進体制であるAICoE事務局メンバー。武蔵大学 特別招聘講師。AI&Marketing BB登壇、新経連AIコミュニティ登壇等。 所属学会 : 日本行動計量学会、人工知能学会、計算社会科学会